Una de las preguntas que más frecuentemente surge al diseñar sistemas distribuidos es cuánto pesa realmente la elección del runtime. No en benchmarks de laboratorio, sino en producción, con pods reales, facturas cloud reales y equipos que tienen que mantener ese sistema a largo plazo.
Este artículo documenta las decisiones de arquitectura detrás de un sistema de gestión empresarial multitenancy desplegado en Kubernetes, usando Go como runtime principal. El caso es concreto, los números son reales.
La elección del runtime no es solo técnica
Cuando se diseña una arquitectura de microservicios, el lenguaje del backend raramente se trata como una variable financiera. Debería serlo.
Cada pod en producción tiene un costo mensual asociado. Ese costo se multiplica con el escalado, con los ambientes (staging, producción, DR), y con el tiempo. La siguiente tabla resume lo que se observa en condiciones reales de idle:
| Runtime | RAM en reposo | Tiempo de arranque |
|---|---|---|
| Go | 10 – 30 MB | < 100ms |
| Node.js | 50 – 80 MB | 200 – 500ms |
| Java (JVM) | 200 – 512 MB | 3 – 10 seg |
| Java (GraalVM) | 50 – 100 MB | < 500ms |
En el sistema analizado, cada microservicio Go corre con esta configuración en producción:
resources:
requests:
memory: "32Mi"
cpu: "10m"
limits:
memory: "128Mi"
cpu: "100m"
Con 10 servicios corriendo, un stack Go ocupa menos de 300MB totales en reposo. El equivalente en Java JVM supera los 2GB solo de overhead de runtime. En un cluster pequeño esa diferencia define si se necesita un nodo adicional o no.
La arquitectura: cómo se construyó por capas
El diseño no surgió completo. Cada iteración resolvió un problema específico. Documentar esa evolución tiene más valor que mostrar solo el resultado final.
Capa 1 — Flujo base y traducción de protocolo
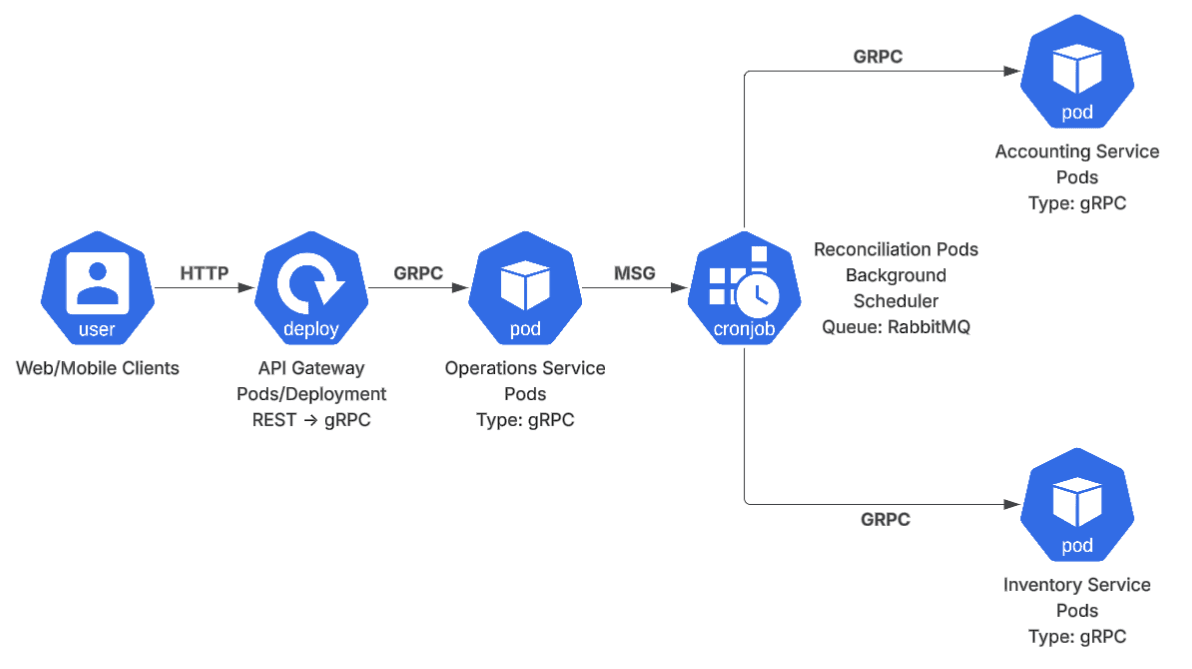
El primer principio de diseño es que el exterior no dicta el interior. El cliente (web o móvil) habla HTTP/REST porque es lo que los browsers y SDKs móviles requieren. Internamente, la comunicación entre servicios usa gRPC.
El API Gateway actúa como el único punto de entrada y hace la traducción REST → gRPC. Esta separación tiene consecuencias prácticas: los servicios internos no cargan con la verbosidad de JSON, no negocian content-types, y operan sobre contratos definidos en archivos .proto que sirven como documentación viva y fuente de generación de código.
Protocol Buffers, el formato de serialización de gRPC, es entre 3 y 10 veces más compacto que JSON equivalente. En servicios que se llaman miles de veces por día, esa diferencia se acumula en latencia y en CPU.
Capa 2 — Descubrimiento dinámico con Nacos
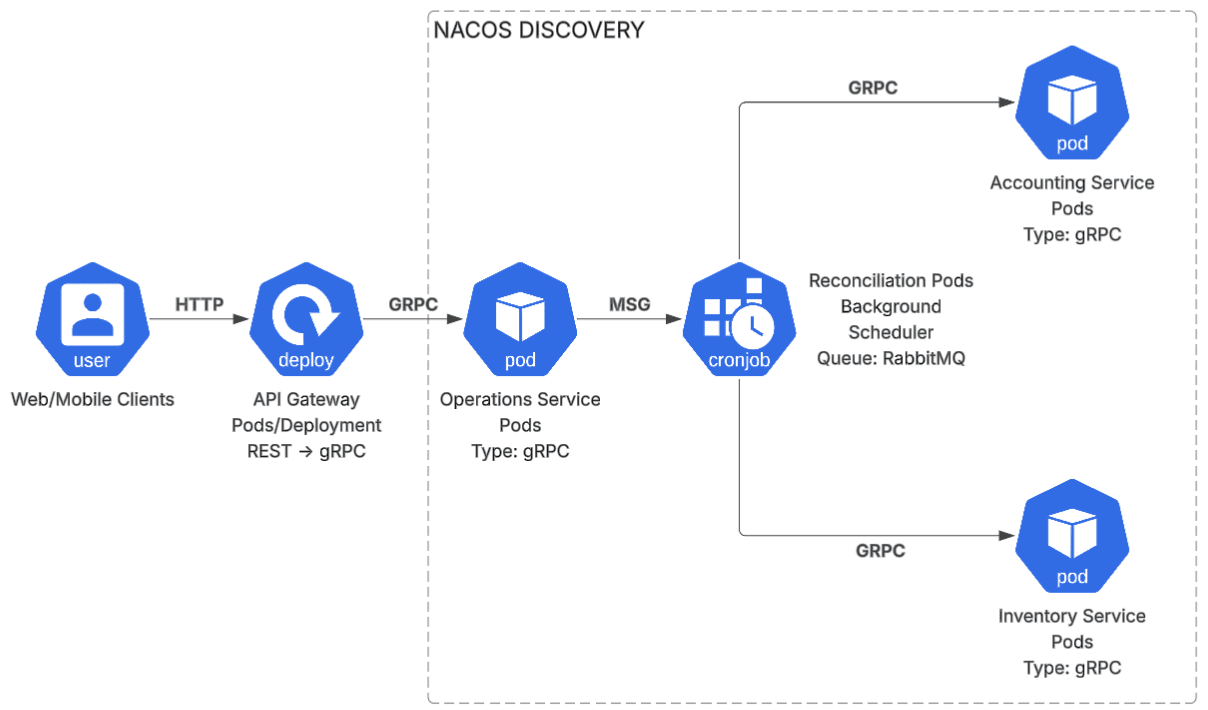
En Kubernetes, los pods no tienen IPs estáticas. Un redeploy, un crash, un escalado horizontal: cualquiera de estos eventos cambia las direcciones de los servicios. Codificar IPs o depender únicamente de los DNS internos de Kubernetes tiene límites cuando se necesita más control sobre el registro, la configuración centralizada y el load balancing a nivel de aplicación.
Nacos cubre ese espacio. Cada servicio se registra al arrancar con su nombre lógico y su IP actual. El consumidor consulta por nombre y obtiene la dirección vigente. Con múltiples réplicas activas, Nacos devuelve la lista completa y el cliente distribuye la carga.
El segundo rol de Nacos en esta arquitectura es como centro de configuración: parámetros de los servicios se pueden actualizar en caliente sin necesidad de redeploy. Esto separa la configuración del ciclo de vida del contenedor.
Capa 3 — Mensajería asíncrona con RabbitMQ
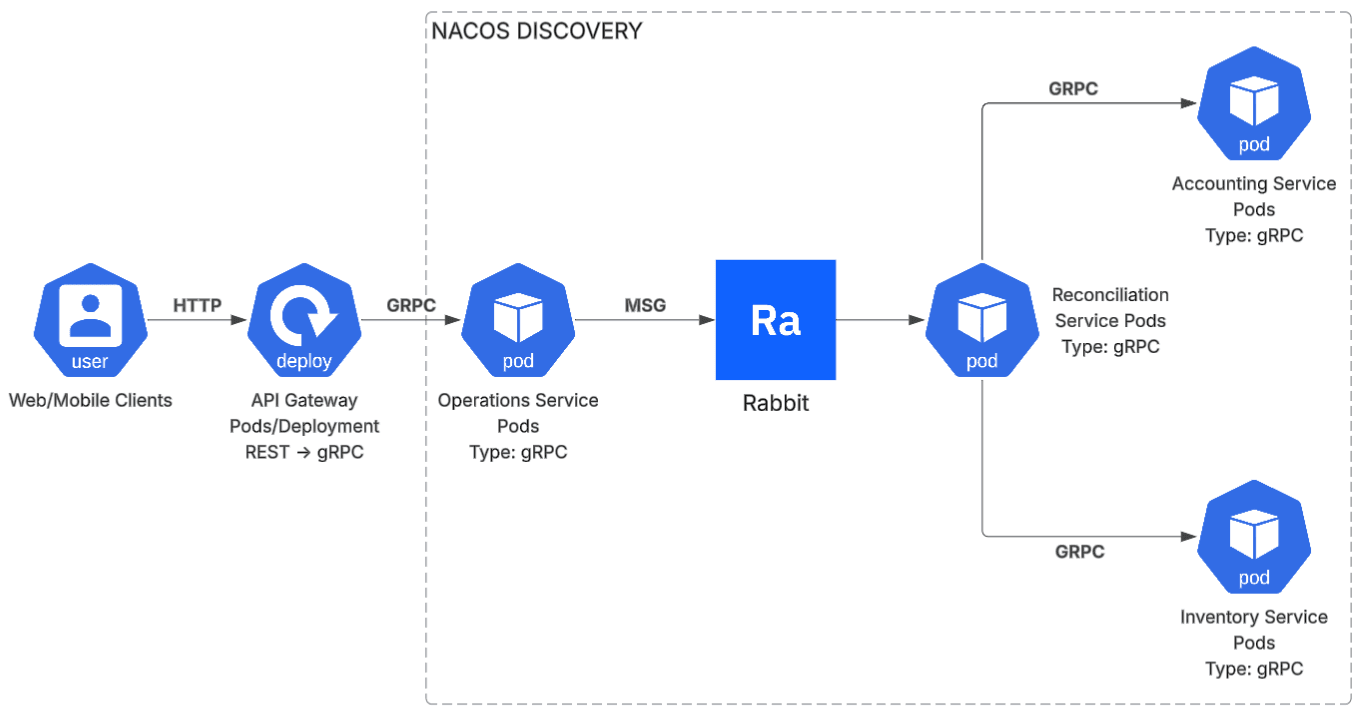
El tercer principio es que no toda operación necesita ser sincrónica. En un sistema de punto de venta, el usuario necesita confirmación inmediata del registro de una venta. No necesita esperar a que se actualice el inventario ni a que se procese la reconciliación contable.
Separar esos flujos es el trabajo de RabbitMQ. El Operations Service publica el mensaje en la cola y responde al usuario. El Reconciliation Service consume el mensaje y coordina las actualizaciones en Accounting e Inventory via gRPC, en segundo plano.
Las ventajas operativas de este patrón son conocidas: tolerancia a fallos parciales (el mensaje espera si un consumer está caído), escalado independiente del producer y los consumers, y un registro natural de intenciones de negocio que facilita auditoría y debugging.
Capa 4 — Seguridad centralizada con Keycloak
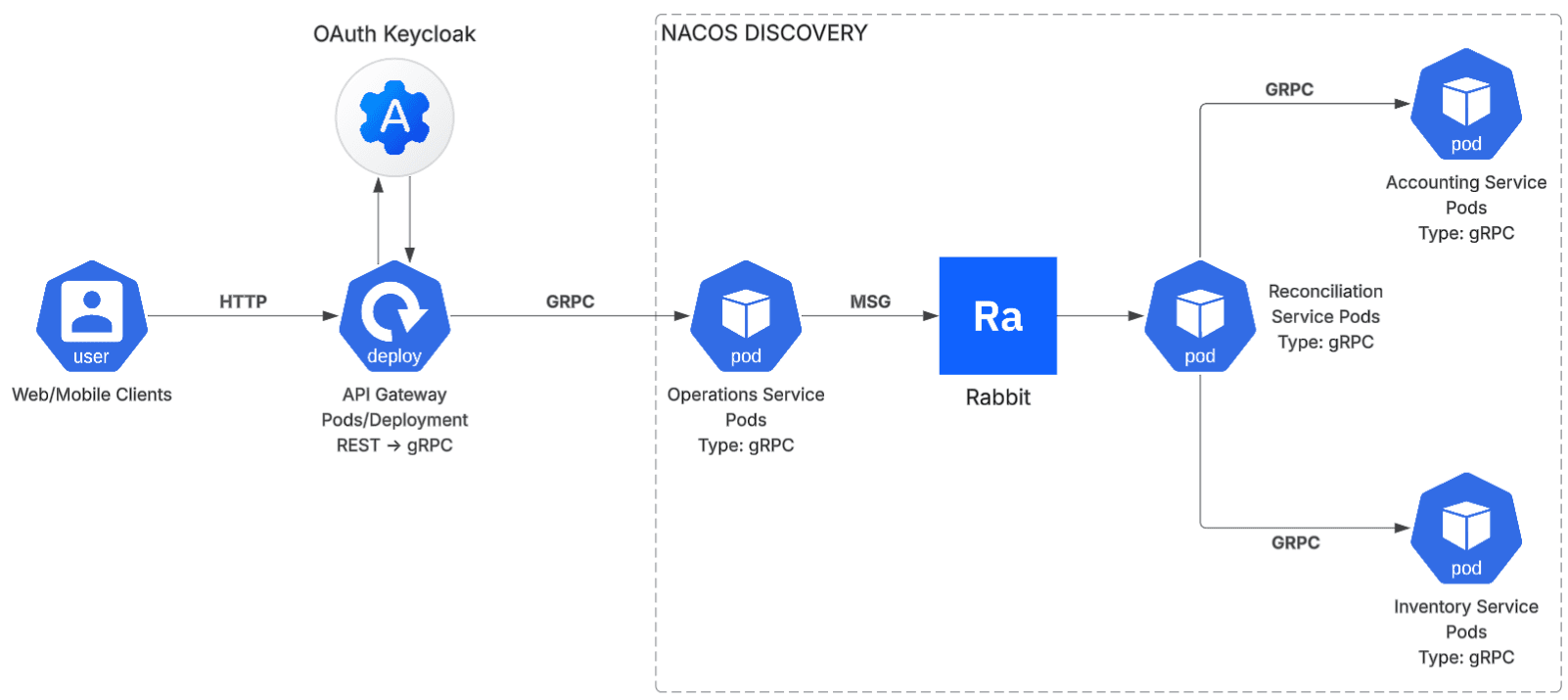
La autenticación y autorización no se implementan servicio por servicio. Se centralizan en el perímetro.
Keycloak actúa como proveedor OAuth2/OpenID Connect. El API Gateway valida el JWT en cada request antes de que este entre al sistema. Los servicios internos reciben el token ya validado y extraen los claims que necesitan (tenant, roles, permisos) sin necesidad de repetir la validación en cada hop.
Para un sistema multitenancy, Keycloak ofrece realms separados por organización, gestión granular de roles, soporte para MFA y federación con directorios externos (LDAP, Active Directory). Se configura una vez, se reutiliza en todos los servicios presentes y futuros.
Capa 5 — Integración de AI con MCP interno
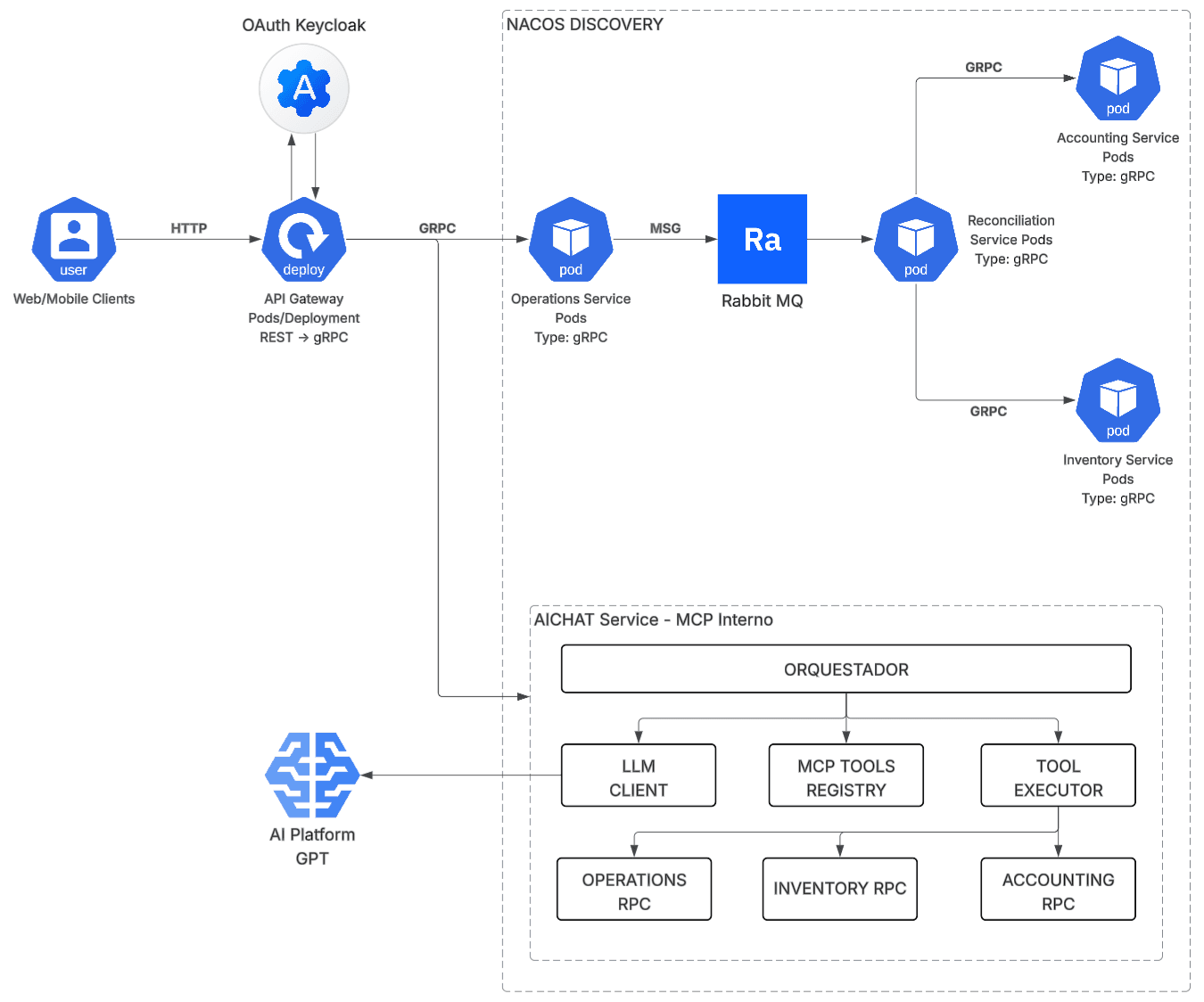
La última capa incorpora un servicio de AICHAT con MCP (Model Context Protocol) interno. La arquitectura de este componente sigue el mismo principio de los demás: un Orquestador central que coordina un cliente LLM (conectado a GPT), un registro de herramientas MCP y un ejecutor que llama directamente los RPCs de Operations, Inventory y Accounting.
El punto arquitectónico relevante aquí es que la capa de AI no tiene acceso directo a la base de datos. Consume los mismos contratos gRPC que usa el resto del sistema. Esto mantiene las reglas de negocio en un solo lugar, hace la integración auditable y permite que la capa de AI evolucione sin tocar los servicios core.
Reflexión sobre el stack
Esta combinación de tecnologías no es la más popular ni la que más aparece en tutoriales. Pero cada pieza resuelve un problema que las alternativas comunes no resuelven igual de bien en conjunto:
Go + gRPC — eficiencia de recursos y contratos fuertes entre servicios. RabbitMQ — desacoplamiento del flujo de usuario y el procesamiento interno. Nacos — descubrimiento dinámico y configuración centralizada sin depender solo de DNS de Kubernetes. Keycloak — seguridad estandarizada en el perímetro, no distribuida en cada servicio.
Lo que vale la pena destacar para cualquier equipo evaluando una arquitectura similar: los números de recursos no son teóricos. Los 32MB de RAM por pod son configuración de producción verificada. La diferencia con un stack JVM equivalente, multiplicada por la cantidad de servicios y ambientes, es el argumento más honesto a favor de Go en este tipo de sistemas.